Notes on Dive into Deep Learning¶
因为毕设的缘故,开始学习沐神的《动手学深度学习》并开始使用mxnet。
《动手学深度学习》电子书地址: Book
根据书中代码复现的每节Notebook: Notebook
2020/01/09 今天把Kaggle上的house pricing刷进了0.11,之前单用Linear Regression得到的结果大概都在0.17左右。后来加上了一个Hidden Layer,units设置为256个。结果在num_epochs和lr都不变的情况下,输出出来的loss曲线就爆炸了QaQ,大概样子就像下面的这个一样:
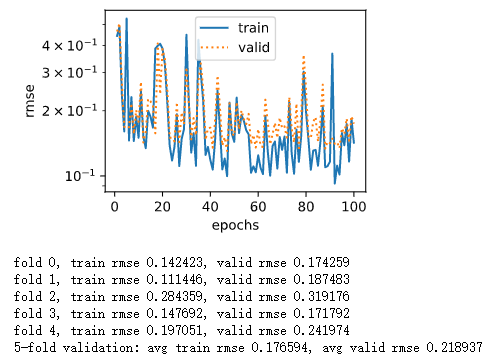
波动很大,train loss和valid rmse也很大。结果我一开始一波智障操作,加大功率,增加epochs,结果就更爆炸了:
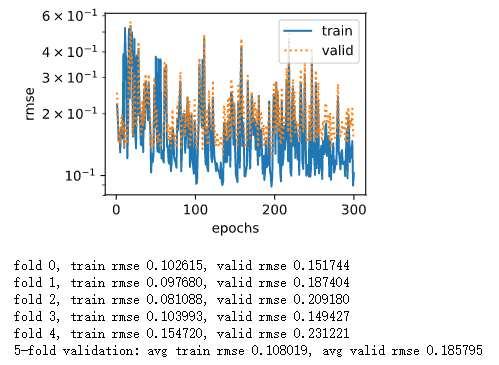
我一开始觉得,哇,这是严重的过拟合啊。后来仔细想了想,loss急剧的波动,应该是lr太大了导致的…(其实我自己没有去验证,没有把真实的weight输出出来看看,如果输出每一步的weight和grad应该就能迅速看出来了)。然后就迅速调整lr,并且降低epochs,结果就变好很多啦,这时基本上降到0.13左右,但是epochs有点大的时候会有轻微的过拟合:
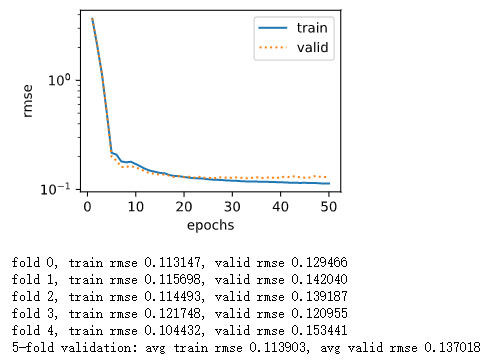
图上面看大概过了20次的时候就开始有点过拟合了,最后开始增加wd(当然在前面的模型里面也加了Dropout),最后调出来最好的一组参:
> k, num_epochs, lr, wd, batch_size = 4, 180, 0.01, 65, 64
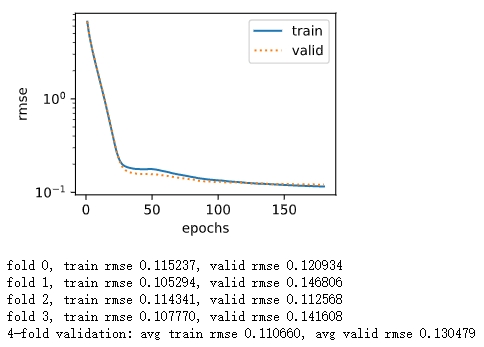
最后,成绩和初始化的参数也有很大关系鸭ouo,同样的参数跑好多遍结果都不一样,和初始化的参数肯定相关。
– 虽然0.118+这个成绩也不是很好,我看见Kaggle上面很多解法都是用集成学习的,有好多教程都用的XGBoost,还有用Random Forests的,但用一个全连接层就调出来0.118+我感觉还是不错的,最主要的是,自己没有事先看过解答和别人的思路。但是带给我更大的困惑就是增加的全连接层到底做了什么,还有整个调参的过程给我一种很玄学的感觉,虽然我在评论区看到mli大神说就是差不多这样子的哈哈
之前也有和别的同学聊过,我感觉数据的预处理有的时候会更加重要一点,但是预处理的过程就…这么说呢,觉得是另一个领域的研究了,和单纯的ML或者DL模型与优化还很不同。某乎上面看过Kaggle的比赛,很多都是数据处理的题目,不能全看成是ML的题目。
之后继续努力叭,LeNet看完,就更迷糊了,虽然能理解卷积层是为了整合或者放大一些特征,池化可以减少位置敏感带来的影响,那具体…卷积的参数好像也是训练出来的…不懂不懂不懂